")
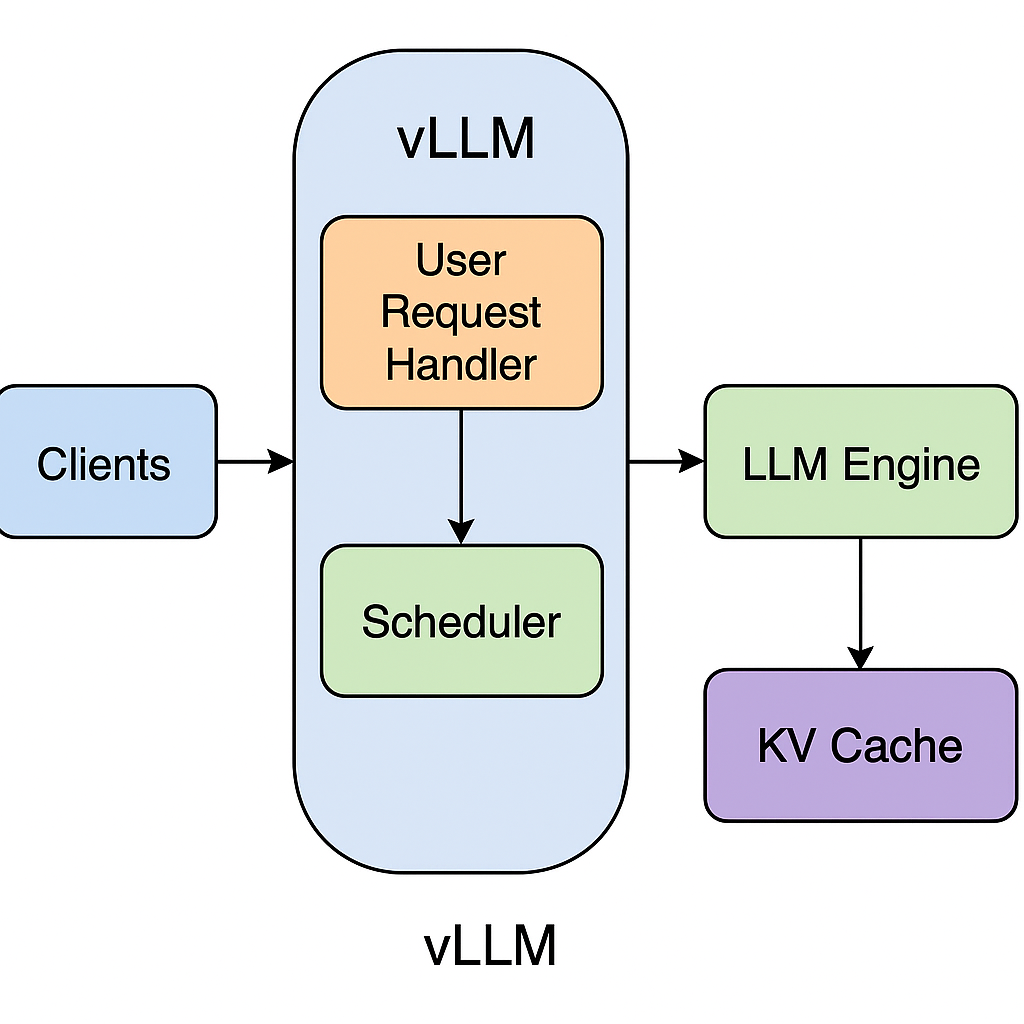
La inteligencia artificial (IA) ha avanzado a pasos agigantados en los últimos años. Hoy, millones de personas interactúan diariamente con modelos grandes de lenguaje, conocidos en inglés como Large Language Models (LLM), como ChatGPT, Gemini, o asistentes inteligentes en buscadores y plataformas de software. Sin embargo, detrás de cada respuesta que ofrecen estas herramientas, hay una infraestructura tecnológica que debe ser rápida, eficiente y escalable.
Uno de los principales desafíos es cómo ofrecer estos modelos de forma eficiente, considerando que pueden tener billones de parámetros, ocupar cientos de gigabytes de memoria RAM en precisión completa (FP32) y requerir aceleradores como GPUs para funcionar correctamente. Aquí es donde entra en juego vLLM, una nueva tecnología que podría convertirse en el motor estándar para ejecutar estos modelos de forma más eficiente.
¿Qué son los LLM y por qué necesitan una infraestructura especial?
Un LLM es una red neuronal entrenada con miles de millones de palabras. Puede generar texto, escribir código, traducir idiomas o responder preguntas complejas.
Como mencionamos anteriormente, el problema radica en que estos modelos son enormes, y no basta con simplemente ‘instalar el modelo’ y utilizarlo. Es necesario desarrollar una infraestructura que permita responder de forma rápida a numerosos usuarios, optimizando al mismo tiempo el uso de recursos.
¿Qué es vLLM?
vLLM es una nueva tecnología de código abierto diseñada para servir modelos de lenguaje de forma más rápida, eficiente y escalable. Su nombre proviene de “virtual LLM”, y su objetivo es maximizar el rendimiento de los LLMs en entornos reales.
Este motor ha sido diseñado por investigadores y desarrolladores con experiencia en inteligencia artificial, y ya está siendo adoptado por empresas y centros de investigación en todo el mundo.
¿Por qué es tan innovador?
1. Sirve múltiples usuarios al mismo tiempo
Normalmente, cuando varias personas hacen preguntas a un modelo como GPT, el sistema las procesa una por una o en grupos. Esto puede generar colas de espera y mucho desperdicio de recursos.
vLLM, en cambio, utiliza una técnica llamada token-level batching. Esto significa que agrupa las preguntas palabra por palabra, permitiendo que muchas respuestas se procesen en paralelo. El resultado: el modelo responde más rápido y con menos uso de GPU.
Veamos cómo funciona. Antes de la introducción de token-level batching, el procesamiento por lotes estático iniciaba un lote completo de preguntas y esperaba a que todas las solicitudes de ese lote finalizaran su cómputo. Sin embargo, como no se sabe cuántos tokens se generarán por cada solicitud, esto provoca que muchas veces las GPUs queden inactivas y subutilizadas durante largos periodos.

En cambio, con el procesamiento a nivel de tokens, no se espera a que todos los lotes terminen antes de comenzar uno nuevo, sino que procesa continuamente nuevas solicitudes en cuanto una pregunta del lote en ejecución termina y hay espacio disponible.

Con esta técnica, las palabras de la siguiente solicitud se empiezan a procesar tan pronto finaliza la anterior solicitud. Fuente: AnyScale.
2. Optimiza la memoria como un experto
Los modelos de lenguaje guardan mucha información intermedia mientras generan una respuesta. Esto se llama KV Cache (Key-Value cache). vLLM gestiona este almacenamiento de forma inteligente y dinámica, usando técnicas similares a cómo los sistemas operativos manejan la memoria.
La KV cache es un componente fundamental dentro de vLLM que optimiza el proceso de generación de texto en modelos grandes de lenguaje. Para generar la siguiente palabra, cada nuevo token generado depende de los tokens previos y sus representaciones internas, que se almacenan en forma de pares clave-valor (keys y values). La KV cache guarda estos pares para evitar recalcular desde cero la representación de los tokens previos.
La KV cache en vLLM facilita la escalabilidad del sistema, ya que reduce el costo computacional y la demanda de memoria durante la generación de texto, haciendo viable la ejecución de modelos muy grandes incluso en hardware con recursos limitados. Gracias a esta optimización, vLLM puede ofrecer tiempos de respuesta rápidos y un uso eficiente de los aceleradores, mejorando la experiencia del usuario y abriendo la puerta a aplicaciones en tiempo real basadas en LLMs.

Con la KV cache, para generar una palabra en un modelo de lenguaje grande, primero, se genera el vector QKV (Query, Key, Value) correspondiente al token que se generó en el paso anterior. Estos vectores son fundamentales para el mecanismo de atención, ya que representan la consulta actual y las claves y valores con los que se compara para decidir qué información es relevante en la generación de la siguiente palabra.
A continuación, se recuperan todos los vectores KV almacenados previamente en la KV cache, que contiene las claves y valores de todos los tokens generados hasta ese momento, evitando así tener que recalcularlos desde cero en cada paso. Con estos datos, el modelo puede calcular la atención, es decir, determinar cómo se relacionan y ponderan los tokens previos para generar el nuevo token de manera coherente y contextual.
Finalmente, una vez generado el nuevo token, sus vectores KV también se almacenan en la caché para ser usados en los pasos siguientes.
Como puedes ver, esta técnica es clave para lograr respuestas rápidas y un rendimiento óptimo en la generación de lenguaje natural.
3. Compatible con herramientas ya existentes
¿Tienes una aplicación que usa la API de OpenAI? vLLM es compatible con ese mismo estándar. Puedes cambiar el backend sin modificar tu frontend. Esto facilita enormemente su integración en empresas o proyectos existentes.
¿Dónde se puede usar vLLM?
vLLM es ideal para todo tipo de aplicaciones que necesiten servir modelos de lenguaje a gran escala:
- Chatbots conversacionales en sitios web
- Asistentes de programación
- Búsquedas inteligentes con lenguaje natural
- Generación de contenido
- Traducción automática
- Aplicaciones educativas y de accesibilidad
- Sistemas de IA integrados en productos empresariales
¿Y cómo lo uso?
Si eres desarrollador o técnico, puedes empezar en cuestión de minutos:
pip install vllm
Y luego lanzar tu servidor:
python -m vllm.entrypoints.openai.api_server --model facebook/opt-1.3b
¡Preparado! Ya puedes enviar preguntas al modelo y obtener respuestas con una velocidad sorprendente.
Conclusión
vLLM no es simplemente otra pieza de software: es una solución moderna para un problema que está creciendo rápidamente. A medida que más empresas y ciudadanos adoptan herramientas basadas en IA, necesitaremos motores que las hagan funcionar sin fricciones. vLLM, con su diseño innovador, podría convertirse en la columna vertebral de la próxima generación de asistentes inteligentes y herramientas generativas.
Leave a Reply